September 24
9:00-10:30
[Workshop] Sustainable HPC State of the Practice Workshop (Sustainable HPC SOP Workshop)
This session is scheduled to start at 9:30.
Room 402
[Tutorial] Embrace Arm and GPU in the datacenter using the NVIDIA Grace Hopper Superchip
Room 404
[Tutorial] Identifying Software Inefficiency with Fine-grained Value Profilers
Room 406
10:45-12:15
[Workshop] LLMxHPC: 2024 International Workshop on Large Language Models (LLMs) and HPC
Room 401
[Workshop] REX-IO 2024: 4th Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads
Room 403
[Workshop] Sustainable HPC State of the Practice Workshop (Sustainable HPC SOP Workshop)
Room 402
[Tutorial] Embrace Arm and GPU in the datacenter using the NVIDIA Grace Hopper Superchip
Room 404
[Tutorial] Best Practices for HPC in the Cloud with AWS and Graviton (Arm) instances
Room 405
[Tutorial] Identifying Software Inefficiency with Fine-grained Value Profilers
Room 406
12:15-13:15
Lunch Break
(Lunch box is provided for attendee)
13:15-14:45
[Workshop] LLMxHPC: 2024 International Workshop on Large Language Models (LLMs) and HPC
Room 401
[Workshop] REX-IO 2024: 4th Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads
Room 403
[Workshop] Sustainable HPC State of the Practice Workshop (Sustainable HPC SOP Workshop)
Room 402
[Tutorial] Embrace Arm and GPU in the datacenter using the NVIDIA Grace Hopper Superchip
Room 404
[Tutorial] Best Practices for HPC in the Cloud with AWS and Graviton (Arm) instances
Room 405
Canceled[Workshop] Cluster Computing - A Sustainable Approach
Room 406
15:00-16:30
[Workshop] Fifth Workshop on Heterogeneous Memory Systems (HMEM)
Room 401
[Workshop] REX-IO 2024: 4th Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads
Room 403
[Workshop] Sustainable HPC State of the Practice Workshop (Sustainable HPC SOP Workshop)
Room 402
[Tutorial] Embrace Arm and GPU in the datacenter using the NVIDIA Grace Hopper Superchip
Room 404
[Tutorial] Best Practices for HPC in the Cloud with AWS and Graviton (Arm) instances
Room 405
[Tutorial] GPU accelerated applications with CUDA-Q: An integrated framework for hybrid classical-quantum computing workloads
Room 406
16:45-18:15
[Workshop] Fifth Workshop on Heterogeneous Memory Systems (HMEM)
Room 401
[Workshop] REX-IO 2024: 4th Workshop on Re-envisioning Extreme-Scale I/O for Emerging Hybrid HPC Workloads
Room 403
[Workshop] Sustainable HPC State of the Practice Workshop (Sustainable HPC SOP Workshop)
Room 402
[Tutorial] Best Practices for HPC in the Cloud with AWS and Graviton (Arm) instances
Room 405
[Tutorial] GPU accelerated applications with CUDA-Q: An integrated framework for hybrid classical-quantum computing workloads
Room 406
|
September 25
9:30-11:00
Opening Session
International Conference Room
Chair: Taisuke Boku (U. Tsukuba)
Welcome address (Satoshi Matusoka, General Co-Chair, RIKEN R-CCS)
TPC report (Mohamed Wahib, TPC Co-Chair, RIKEN R-CCS)
Keynote (1): Estela Suarez
International Conference Room
Chair: Kengo Nakajima (U.Tokyo/RIKEN R-CCS)
11:30-13:00
Best Paper Finalists
International Conference Room
Chair: Mohamed Wahib (RIKEN R-CCS)
GPU Reliability Assessment: Insights Across the Abstraction Layers
GPU Reliability Assessment: Insights Across the Abstraction Layers
Lishan Yang (George Mason University), George Papadimitriou (University of Athens), Dimitrios Sartzetakis (University of Athens), Adwait Jog (University of Virginia), Evgenia Smirni (William & Mary), Dimitris Gizopoulos (University of Athens)
Abstract
Graphics Processing Units (GPUs) are widely deployed and utilized across various computing domains including cloud and high-performance computing. Considering its extensive usage and increasing popularity, ensuring GPU reliability is crucial. Software-based reliability evaluation methodologies, though fast, often neglect the complex hardware details of modern GPU designs. This oversight could lead to misleading measurements and misguided decisions regarding protection strategies. This paper breaks new ground by conducting an in-depth examination of well-established vulnerability assessment methods for modern GPU architectures, from the microarchitecture all the way to the software layers. It highlights divergences between popular software-based vulnerability evaluation methods and the ground truth cross-layer evaluation, which persist even under strong protections like triple modular redundancy. Accurate evaluation requires considering fault distribution from hardware to software. Our comprehensive measurements offer valuable insights into accurate assessment of GPU reliability.
Siesta: Synthesizing Proxy Applications for MPI Programs
Siesta: Synthesizing Proxy Applications for MPI Programs
Jiyu Luo (Univeristy of Science and Technology of China), Tao Yan (Univeristy of Science and Technology of China), Qingguo Xu (University of Science and Technology of China), Jingwei Sun (University of Science and Technology of China), Guangzhong Sun (University of Science and Technology of China)
Abstract
Proxy applications (proxy-apps) are basic tools for evaluating the performance of specific workloads on high- performance computing (HPC) systems. Since the development of high-fidelity proxy-apps, which exhibit similar performance char- acteristics as corresponding production applications, is labor- intensive, synthetic proxy-apps are created as a useful supplement to manually developed proxy-apps. To thoroughly resemble performance characteristics of HPC applications represented by Message Passing Interface (MPI) programs, we propose Siesta, a novel framework to automatically synthesize proxy- apps based on communication-computation traces. Given an MPI program, Siesta synthesizes parameterized code snippets to mimic computation behaviors in different execution periods, and combines the code snippets and MPI function records into an event trace. It then extracts program behavior patterns from the trace as grammars and finally transforms the grammars into a synthetic proxy-app. We evaluate the proposed methods on representative MPI programs with various environments. The results show that our synthetic proxy-apps can precisely approximate the performance characteristics of MPI programs.
Distributed Order Recording Techniques for Efficient Record-and-Replay of Multi-threaded Programs
Distributed Order Recording Techniques for Efficient Record-and-Replay of Multi-threaded Programs
Xiang Fu (Nanchang Hangkong University), Shiman Meng (Nanchang Hangkong University), Weiping Zhang (Nanchang Hangkong University), Luanzheng Guo (Pacific Northwest National Laboratory), Kento Sato (RIKEN R-CCS), Dong H. Ahn (NVIDIA), Ignacio Laguna (LLNL), Gregory L. Lee (LLNL), Martin Schulz (Technical University of Munich)
Abstract
As OpenMP increasingly becomes the common practice in parallel programming, its greater levels of non-deterministic execution makes debugging and testing more challenging. The ability to record and deterministically replay program execution is key to address this challenge. However, scalably replaying OpenMP programs is still an unresolved problem. In this paper, we propose two novel techniques that use Distributed Clock (DC) and Distributed Epoch (DE) recording schemes to eliminate excessive thread synchronization for OpenMP recording and replay. Our evaluation on representative HPC applications with ReOMP, which we used to realize DC and DE recording, shows that our approach is 2-5x more efficient than traditional approaches that synchronize on every shared memory access. Furthermore, we demonstrate that our approach can be easily combined with MPI-level replay tools to replay non-trivial MPI+OpenMP applications. We achieve this by integrating ReOMP into ReMPI, an existing scalable MPI record-and-replay tool, with only a small MPI-scale-independent runtime overhead.
13:00-14:00
Student Networking Lunch
(Lunch box is provided for attendee)
International Conference Room Room 401/402
Lunch Break
(Lunch box is provided for attendee)
Room 401/402 International Conference Room
14:00-15:30
Session (1) Graph Algorithms & GNNs
International Conference Room
Chair: Lishan Yang (GMU)
FTGraph: A Flexible Tree-based Graph Store on Persistent Memory for Large-Scale Dynamic Graphs
FTGraph: A Flexible Tree-based Graph Store on Persistent Memory for Large-Scale Dynamic Graphs
Gan Sun (University of Chinese Academy of Sciences), Jiang Zhou (University of Chinese Academy of Sciences), Shuibing He (Zhejiang University), Bo Li (Institute of Information Engineering, CAS), Xiaoyan Gu (Institute of Information Engineering, CAS), Weiping Wang (Institute of Information Engineering, CAS)
Abstract
Traditional in-memory graph systems often suffer from scalability due to the limited capacity and volatility of DRAM. Emerging non-volatile memory (NVM) provides an opportunity to achieve highly scalable and high-performance graph stores for its large capacity and persistence characteristics. However, directly deploying current in-memory graph storage systems on NVM would cause significant inefficiencies in NVM access, as their graph organization designed for DRAM may incur higher write amplification, crash inconsistency and costly concurrency control overhead in NVM for write-intensive workloads. In this paper, we propose FTGraph, a Flexible Tree-based Graph storage system, for both efficient dynamical graph updates and analysis. To achieve this goal, we introduce a novel degree-aware suffix bit tree to effectively manage vertices and edges of the graph, enabling adaptability to real-world power-law degree distributions while significantly reducing NVM writes. Based on it, we adopt two optimization methods, logical vertex ID translation and sequential storage, for vertices with very high degrees within the tree to enhance graph analysis operations. We further integrate 8B NVM atomic writes with optimistic version-based concurrency control through a dual bitmap design to ensure low-overhead, log-free crash consistency and reduce read-writer contention. Experimental results show that FTGraph achieves up to 21.2$\times$ higher update performance and up to 85.4$\times$ higher analysis performance, compared with state-of-the-art dynamic graph systems implemented on NVMs.
PGSampler: Accelerating GPU-based Graph Sampling in GNN Systems via Workload Fusion
PGSampler: Accelerating GPU-based Graph Sampling in GNN Systems via Workload Fusion
Xiaohui Wei (Jilin University), Weikai Tang (Jilin University), Hao Qi (Huazhong University of Science and Technology), Hengshan Yue (Jilin University)
Abstract
Graph Neural Networks (GNNs) have demonstrated remarkable performance across various domains. Sample-based training, a practical strategy for training on large-scale graphs, often faces time-consuming graph sampling challenges. To ad- dress this, GPU-based graph sampling has been introduced, while there is still room for further efficiency improvements. Though several prior works have been proposed to accelerate the compu- tation or memory access for GPU-based graph sampling, we show that the performance bottlenecks induced by small workload cannot be ignored. In this paper, we propose PGSampler, an efficient system for accelerating GPU-based graph sampling. First, PGSampler leverages a barrier-free execution mode to fuse workload, significantly improving the resource utilization. By altering the sampling execution mode, PGSampler also reduces the preprocessing time before kernel execution, thus accelerating the whole sampling process. Next, based on the new sampling execution mode, considering the dynamically generated nature of sampling tasks, PGSampler adopts a persistent kernel design and uses the task queue to assign tasks, achieving dynamic load balancing. Evaluations with diverse parameter settings show that PGSampler can achieve up to 2.22× performance speedup over the state-of-the-art GNN system DGL.
MassiveGNN: Efficient Training via Prefetching for Massively Connected Distributed Graphs
MassiveGNN: Efficient Training via Prefetching for Massively Connected Distributed Graphs
Aishwarya Sarkar (Iowa State University), Sayan Ghosh (Pacific Northwest National Laboratory), Nathan Tallent (Pacific Northwest National Laboratory), Ali Jannesari (Iowa State University)
Abstract
Graph Neural Networks (GNN) are indispensable in learning from graph-structured data, yet their rising computational costs, especially on massively connected graphs, pose significant challenges in terms of execution performance. To tackle this, distributed-memory solutions such as partitioning the graph to concurrently train multiple replicas of GNNs are in practice. However, approaches requiring a partitioned graph usually suffer from communication overhead and load imbalance, even under optimal partitioning and communication strategies due to irregularities in the neighborhood minibatch sampling. This paper proposes practical trade-offs for improving the sampling and communication overheads for representation learning on distributed graphs (using popular GraphSAGE architecture) by developing a parameterized prefetch and eviction scheme on top of the state-of-the-art Amazon DistDGL distributed GNN framework, demonstrating about 15--40% improvement in end-to-end training performance on the NERSC Perlmutter supercomputer for various OGB datasets.
Session (2) Performance Modeling
Room 401/402
Chair: Filippo Spiga (Nvidia)
A Protocol to Assess the Accuracy of Process-Level Power Models
A Protocol to Assess the Accuracy of Process-Level Power Models
Emile Cadorel (Davidson consulting), Dimitri Saingre (Davidson consulting)
Abstract
The energy consumption of servers has been a critical research area, drawing significant interest from academic and industrial sectors. Various models have been developed to estimate power consumption of computing devices, ranging from simple linear models to more complex ones. In recent years, as the cloud paradigm has expanded and allowed applications to be hosted alongside others in virtual machines, power models have evolved to distribute energy usage among applications on a server. These models aim to achieve two primary objectives: monitoring the energy footprint and optimizing energy consumption. Nonetheless, little attention has been given in academic literature to evaluate the efficiency and accuracy of the allocation phase of this models. This paper presents a definition of power division and a protocol to evaluate models using such division. The proposed protocol is used to evaluate models on physical machines with different performance settings, toggling hyperthreading and turboboost. Before discussing the conceptual distinctions between power and energy allocation models, our results show the existence of some limitations in the existing models. These results provide valuable insight into the missing information needed to improve the accuracy of power models.
Holistic Performance Analysis for Asynchronous Many-Task Runtimes
Holistic Performance Analysis for Asynchronous Many-Task Runtimes
Omri Mor (University of Illinois Urbana–Champaign), George Bosilca (Nvidia Corporation), Marc Snir (University of Illinois Urbana–Champaign)
Abstract
There has been a renewed interest in Asynchronous Many-Task (AMT) computation runtimes due to increasingly heterogeneous computing resources and complex application logic. However, AMT scheduling is typically non-deterministic, and their task dependency graphs are complex and irregular, making it difficult to identify performance bottlenecks using current performance tools and analysis methodologies. This paper presents a new performance analysis methodology and a performance sampling tool that combines data from both computation and communication to support this methodology. The tool is integrated with the PaRSEC runtime. To illustrate the approach, the performance analysis of HiCMA, a state-of-the-art tile-based low-rank Cholesky factorization package, was conducted. The analysis identified bottlenecks in both the PaRSEC runtime and the application itself and suggested changes necessary to overcome them. After implementing the changes, there was up to a 1.45x speedup in time-to-solution when strong-scaling the application.
Automated approach for accurate CPU power modelling
Automated approach for accurate CPU power modelling
Tomé Maseda (Universidade da Coruña), Jonatan Enes (Universidade da Coruña), Roberto R. Expósito (Universidade da Coruña), Juan Touriño (Universidade da Coruña)
Abstract
Power supply is a limiting factor when increasing the computing capacity of supercomputers. As a consequence, power consumption has become one of the biggest challenges in the field of High Performance Computing (HPC). In order to develop energy-efficient tools (e.g., frameworks, applications), it is essential to have an accurate power consumption modelling. Although previous works proposed a wide variety of approaches to model CPU power consumption, building models in an automated and adaptable way to changing scenarios and predicting power with high precision remains complex due to multiple factors (e.g., training and test workloads, model variables). In this paper, we present a set of tools to fully automate the process of modelling power consumption using CPU time series data. More specifically, our proposal includes: (1) CPUPowerWatcher, which gathers CPU metrics during the execution of user-configurable workloads; and (2) CPUPowerSeer, which builds models to predict CPU power consumption (e.g., polynomial regression) from different CPU variables (e.g., usage, clock frequency) using time series data. Thus, multiple models can be created and evaluated easily, allowing the selection of an optimal model for a specific workload. The experiments conducted by combining these tools allow analyzing the impact of novel factors on CPU power consumption, such as the type of CPU usage generated by different workloads or how the CPU cores are allocated to them. In addition, the accuracy of six regression models is compared when predicting CPU- and I/O-intensive workloads using two different core allocations.
16:00-16:30
Poster Indexing (30 min)
International Conference Room
|
September 26
9:30-10:30
Keynote (2): Rio Yokota
International Conference Room
Chair: Miwako Tsuji (RIKEN R-CCS)
11:00-12:30
Session (3) Networks & Communication
International Conference Room
Chair: Seydou Ba (RIKEN R-CCS)
MPI Collective Algorithm Selection in the Presence of Process Arrival Patterns
MPI Collective Algorithm Selection in the Presence of Process Arrival Patterns
Majid Salimi Beni (University of Salerno), Biagio Cosenza (University of Salerno), Sascha Hunold (TU Wien)
Abstract
The Message Passing Interface (MPI) is a programming model for developing high-performance applications on large-scale machines. A key element of MPI is its collective communication operations. While the MPI standard defines the semantics of these operations, it leaves the algorithmic implementation to the MPI libraries. Each MPI library contains various algorithms for each collective, and selecting the best algorithm typically relies on performance metrics obtained from micro-benchmarks. In such micro-benchmarks, processes are typically synchronized using MPI_Barrier before invoking a collective operation. However, in real-world scenarios, processes often arrive at a collective in diverse patterns, often due to resource contention. The performance of collective algorithms can vary significantly depending on the arrival pattern type. In this work, we address the challenge of selecting the most efficient algorithm for a given collective, taking into account process arrival patterns. First, we demonstrate through a simulation study that arrival patterns significantly influence the choice of the optimal collective algorithm for specific communication instances. Second, we conduct a comprehensive micro-benchmark analysis to illustrate the sensitivity of MPI collectives to these arrival patterns. Third, we show that our innovative micro-benchmarking methodology is effective in selecting the best-performing collective algorithm for real-world applications.
Optimizing Neighbor Collectives with Topology Objects
Optimizing Neighbor Collectives with Topology Objects
Gerald Collom (University of New Mexico), Derek Schafer (University of New Mexico), Amanda Bienz (University of New Mexico), Patrick Bridges (University of New Mexico), Galen Shipman (Los Alamos National Laboratory)
Abstract
Many HPC applications implement non-cartesian neighbor data exchanges using MPI point-to-point operations rather than utilizing native MPI neighbor collective methods. Each application must therefore implement their own communication optimizations, rather than leveraging any optimizations that could be provided by MPI. Currently, applications avoid neighbor collectives due to the lack of performance optimizations within them along with large costs associated with graph communicator formation. This paper presents a new approach for creating local, non-cartesian topology objects that provide finer control over the aforementioned setup costs, which can be deferred until additional information about how and how often the topology will be used is available. Additionally, these first-class MPI topology objects enable communication optimizations through locality-awareness within the neighborhood collective initialization call, and optimize iterative communication calls through aggregation. This paper describes our implementation within an MPI extension library and demonstrates the effectiveness of our approach in simple benchmarks and real-world applications.
A Topology- and Load-Aware Design for Neighborhood Allgather
A Topology- and Load-Aware Design for Neighborhood Allgather
Hamed Sharifian (Queen's University), Amirhossein Sojoodi (Queen's University), Ahmad Afsahi (Queen's University)
Abstract
Neighborhood collective communications were introduced in MPI 3.0 to enable application developers to define new communication patterns and take advantage of the sparsity in the communication patterns of applications. In this research, we propose a novel topology- and load-aware distance-halving design for neighborhood allgather. In this algorithm, each rank recursively halves the communicator and finds an agent on the opposite half to offload its outgoing neighbors. This approach limits communication with distant ranks, thereby decreasing the latency of neighborhood allgather. Our experimental study demonstrates that the algorithm can outperform the default implementation of Open MPI with up to a 33x speedup for various message sizes in both Moore and Random-Sparse-Graph micro-benchmarks. Furthermore, our design exhibits up to 4.92x performance gain for the Sparse Matrix Multiplication Kernel.
Session (4) Numerical Libraries
Room 401/402
Chair: Emil Vatai (RIKEN R-CCS)
Uncut-GEMMs : Communication-aware matrix multiplication on multi-GPU nodes
Uncut-GEMMs : Communication-aware matrix multiplication on multi-GPU nodes
Petros Anastasiadis (National Technical University of Athens), Nikela Papadopoulou (University of Glasgow), Nectarios Koziris (National Technical University of Athens), Georgios Goumas (National Technical University of Athens)
Abstract
General Matrix Multiplication (GEMM) is one of the most common kernels in high-performance computing (HPC) and machine-learning (ML) applications, frequently dominating their execution time, rendering its performance vital. As multi-GPU nodes have become common in modern HPC systems, GEMM is usually offloaded on GPUs as its compute-intensive nature is a good match for their architecture. On the other hand, despite the GEMM kernel itself being usually compute-bound, execution on multi-GPU systems also requires fine-grained communication and task scheduling to achieve optimal performance. While numerous multi-GPU level-3 BLAS libraries have faced these issues in the past, they are bound by older design concepts that are not necessarily applicable to modern multi-GPU clusters, resulting in considerable deviation from peak performance. In this work, we thoroughly analyze the current challenges regarding data movement, caching, and overlap of multi-GPU GEMM, and the shortcomings of previous solutions, and provide a fresh approach to multi-GPU GEMM optimization. We devise a static scheduler for GEMM, enabling a variety of algorithmic, communication, and auto-tuning optimizations, and integrate those in an end-to-end open-source multi-GPU GEMM library. Our library is evaluated on a multi-GPU NVIDIA HGX system with 8 NVIDIA A100 GPUs, achieving on average a 1.37x and 1.29x performance improvement over the state-of-the-art multi-GPU GEMM libraries, for double and single precision, respectively.
Generating High-Performance FFT Code through MLIR Linalg Dialect and Micro-Kernel Optimization
Generating High-Performance FFT Code through MLIR Linalg Dialect and Micro-Kernel Optimization
Yifei He (KTH Royal Institute of Technology), Stefano Markidis (KTH Royal Institute of Technology)
Abstract
Fast Fourier Transform (FFT) libraries are an indispensable and critical component of any High-Performance Computing (HPC) software stacks. They are used in a large spectrum of applications, ranging from PDE solvers and signal spectral analysis. To design and develop the next-generation HPC FFT libraries, it is critical to leverage modern computer architectures, which include features such as SIMD operations, along with modern compiler infrastructure like MLIR and LLVM. In this work, we introduce FFTc 2.0, an MLIR-based domain-specific compilation framework for FFT. We have extended the MLIR Linalg dialect with FFT-specific operations to harness high-level tensor-based abstractions for FFT. These abstractions are ideal for articulating various FFT algorithms and facilitating formula rewriting for FFT decomposition and cache-friendly optimization. To achieve exceptional performance—particularly in response to the limited support for complex arithmetic in MLIR and the general-purpose compiler LLVM—we employ micro-kernels. These micro-kernels are designed to implement small-size FFT kernels for integration into larger FFTs. They utilize SIMD-friendly data layouts for complex arithmetic and feature optimized memory access patterns, enabling performance enhancements not achievable with standard compiler implementations. Our method achieves performance levels that are comparable to or surpass those of widely-used FFT libraries, such as FFTW. Additionally, it establishes a robust software infrastructure that facilitates further optimizations and supports additional hardware backends.
Understanding Mixed Precision GEMM with MPGemmFI: Insights into Fault Resilience
Understanding Mixed Precision GEMM with MPGemmFI: Insights into Fault Resilience
Bo Fang (Pacific Northwest National Laboratory), Xinyi Li (University of Utah), Harvey Dam (University of Utah), Cheng Tan (Google), Siva Kumar Sastry Hari (NVIDIA), Timothy Tsai (NVIDIA), Ignacio Laguna (Lawrence Livermore National Laboratory), Dingwen Tao (Indiana University), Ganesh Gopalakrishnan (University of Utah), Prashant J. Nair (University of British Columbia), Kevin Barker (Pacific Northwest National Laboratory), Ang Li (Pacific Northwest National Laboratory)
Abstract
Emerging deep learning workloads urgently need fast general matrix multiplication (GEMM). Thus, one of the critical features of machine-learning-specific accelerators such as NVIDIA Tensor Cores, AMD Matrix Cores, and Google TPUs is the support of mixed-precision enabled GEMM. For DNN models, lower-precision \fp data formats and computation offer acceptable correctness but significant performance, area, and memory footprint improvement. While promising, the mixed-precision computation on error resilience remains unexplored. To this end, we develop a fault injection framework that systematically injects fault into the mixed-precision computation results. We investigate how the faults affect the accuracy of machine learning applications. Based on the characteristics of error resilience, we offer lightweight error detection and correction solutions that significantly improve the overall model accuracy by 75% if the models experience hardware faults. The solutions can be efficiently integrated into the accelerator's pipelines.
12:30-13:30
Lunch Break
(Lunch box is provided for attendee)
International Conference Room
Student Networking Lunch
(Lunch box is provided for attendee)
Room 401/402
13:30-15:00
Session (5) IoT, Cloud, and Data Center (1 of 2)
International Conference Room
Chair: Matthew Dearing (UIC) Ryohei Kobayashi (University of Tsukuba)
Parallelism or Fairness? How to be friendly for SSDs in cloud environments
Parallelism or Fairness? How to be friendly for SSDs in cloud environments
Yang Zhou (Huazhong University of Science and Technology), Fang Wang (Huazhong University of Science and Technology), Zhan Shi (Huazhong University of Science and Technology), Dan Feng (Huazhong University of Science and Technology)
Abstract
Modern SSDs achieve low latency and high throughput by utilizing multiple levels of SSD parallelism. In cloud environments, fairness is also a critical design consideration and has drawn great interest in recent years. However, we find that excessive SSD parallelism can inadvertently impair the fairness of SSDs due to the striped data layout. We observe from our experimental analysis that some common access patterns in cloud loads (e.g., high-intensity I/O) are not addressed by SSD parallelism, which can affect both SSD parallelism and fairness. In this paper, we analyze two address mapping policies with orthogonal characteristics from the perspectives of SSD parallelism and fairness. Based on extensive experiments and observations, we schedule a hybrid address mapping policy to achieve fairness of SSDs in cloud environments by distinguishing different I/O access modes and cold/hot data, while ensuring SSD performance. Experimental results on the latest block-level I/O traces show that our approach significantly improves performance and fairness by up to 77.3% and 62.8%, respectively, over the previous schemes with negligible cost. Meanwhile, it can also reduce the write amplification by 23.5% to 33.5%.
SLACKVM: Packing Virtual Machines in Oversubscribed Cloud Infrastructures
SLACKVM: Packing Virtual Machines in Oversubscribed Cloud Infrastructures
Pierre Jacquet (Inria), Thomas Ledoux (IMT Atlantique), Romain Rouvoy (Université de Lille)
Abstract
Cloud providers generally expose a large catalog of Virtual Machines (VMs) offers, some being categorized as premium—guaranteeing dedicated resources—and others being hosted in oversubscribed environments, where virtual resources can exceed the physical capabilities of Physical Machines (PMs). The latter strategy is often employed to increase platform utilization, as hosted VMs are unlikely to fully utilize all their allocated resources simultaneously [1]. However, managing multiple oversubscribed VM levels introduces an additional layer of complexity for Cloud providers, often leading them to provision isolated clusters of PMs for each category of offers. In this paper, we introduce SLACKVM, a novel Cloud shared architecture wherein VMs from various oversubscription levels coexist on the same cluster of PMs. In particular, we demonstrate that oversubscription levels can be complementary, meaning they do not saturate the same resource components. By leveraging this complementarity, Cloud providers can couple multiple levels to better consolidate VMs offers onto PMs, and reduce the size of their clusters by up to 9.6%. This resource savings results in both an operational cost reduction and a reduced ecological footprint for Cloud infrastructures, with a limited impact on the Quality of Service (QoS).
RL-Cache: An Efficient Reinforcement Learning based Cache Partitioning Approach for Multi-tenant CDN Services
RL-Cache: An Efficient Reinforcement Learning based Cache Partitioning Approach for Multi-tenant CDN Services
Ranhao Jia (Shanghai Jiao Tong University), Zixiao Chen (Shanghai Jiao Tong University), Chentao Wu (Shanghai Jiao Tong University), Jie Li (Shanghai Jiao Tong University), Minyi Guo (Shanghai Jiao Tong University), Hongwen Huang (Tencent Holdings Limited)
Abstract
Content Delivery Network (CDN) has been widely used to provide data transmission services to end users. The edge cache servers are an important infrastructure in CDN, and their hit ratios significantly influence the Quality of Service (QoS), especially access latency and throughput. However, edge caches are typically shared by multiple tenants (i.e., Internet Content Providers or ICPs) and the resource contention among tenants presents a huge challenge to meet the QoS requirements. Cache partitioning is a common method to deal with this challenge, and several approaches have been proposed but still have some drawbacks. Existing methods bring non-negligible temporal and spatial overheads while obtaining locality metrics. Although some learning based methods have reduced aforementioned costs, the learning model convergence is slow due to the large searching space. To address the above problems, we propose a lightweight Reinforcement Learning based Cache Partitioning Approach (RL-Cache), which increases overall hit ratios of edge cache servers in CDN. The core of RL-Cache is a new feature named Compulsory Miss Ratio (CMR). It can be obtained in linear complexity and reflect directions for adjusting cache space. To demonstrate the effectiveness of our approach, we collect traces from Tencent Cloud CDN and develop a simulator to conduct several experiments. The experimental results show that compared to state-of-the-art methods, RL-Cache increases hit ratio by 1.94% and hit traffic size by 21.52% on average.
Session (6) Runtime Optimizations
Room 401/402
Chair: Yuan He (RIKEN R-CCS)
FCUFS: Core-Level Frequency Tuning for Energy Optimization on Intel Processors
FCUFS: Core-Level Frequency Tuning for Energy Optimization on Intel Processors
Hongjian Zhang (Shanghai Jiao Tong University), Akira Nukada (University of Tsukuba), Qiucheng Liao (Shanghai Jiao Tong University)
Abstract
Sacrificing minor performance for better energy efficiency is effective in reducing the energy consumption of supercomputers. Recent studies have utilized some frequency tuning and power capping features of Intel processors to decrease energy consumption in supercomputers. However, two main issues persist: 1) current methods do not account for variability between cores, leading to insufficient energy savings in mixed workloads; and 2) they fail to control the extent of performance loss following frequency tuning. To address these issues, we developed the FCUFS framework, which includes two components: 1) a neural network for predicting performance and power; and 2) a strategy optimization algorithm for selecting frequencies with controllable performance loss. We evaluated FCUFS on Intel mainstream processors across 15 dedicated workloads and 5 mixed workloads. On a single dual-socket Ice Lake-SP server, at a 5% performance loss target, the average energy savings were 11.4% for dedicated workloads and 13.8% for mixed workloads, with average performance losses of 2.9% and 3.5%, respectively. At a 10% performance loss target, the energy savings increased to 14.2% for dedicated workloads and 14.4% for mixed workloads, with performance losses of 8.7% and 9.4%, respectively. When scaling up to 2,048 cores, the average energy savings were 9.7% with 4.4% performance loss. The results show that FCUFS achieves consistent energy savings across dedicated and mixed workloads while maintaining controllable performance loss.
ML-based Dynamic Operator-Level Query Mapping for Stream Processing Systems in Heterogeneous Computing Environments
ML-based Dynamic Operator-Level Query Mapping for Stream Processing Systems in Heterogeneous Computing Environments
Sejeong Oh (Sogang University), Gordon Euhyun Moon (Sogang University), Sungyong Park (Sogang University)
Abstract
Mapping queries to optimal computing devices at the operator-level presents a significant challenge in stream processing systems (SPS) with heterogeneous computing resources. Inefficient query mapping can degrade the performance of the SPS. To address this issue, existing approaches utilize static methods like mapping all queries to either CPUs or GPUs, or maintaining static mapping tables for queries or operators based on their predetermined device preferences. However, the static mapping scheme fails to offer an optimal solution, as the device preference for different query operators changes dynamically at runtime. In this paper, we propose DYNO, a high-performance SPS that dynamically maps queries to devices at the operator-level using a tree-based machine learning algorithm. To effectively determine an optimized device mapping plan for query operators, DYNO employs a tree-based gradient boosting model to accurately predict the execution time for all potential mapping plan combinations. DYNO also introduces a novel turn-based updating scheme to effectively maximize performance in stream processing while training a tree-based gradient boosting model. Additionally, we devise an efficient device mapping scheme to expedite the process of determining the optimal device mapping plan, leveraging the direct acyclic graph (DAG) algorithm. Our DYNO completely hides any overhead caused by the extra computation to find the optimal plan by utilizing prefetching and GPU idle periods. Experimental results using a variety of queries and traffic patterns show that our DYNO outperforms existing state-of-the-art approaches by ensuring high throughput, low latency, and highly reliable processing.
Enabling Practical Transparent Checkpointing for MPI: A Topological Sort Approach
Enabling Practical Transparent Checkpointing for MPI: A Topological Sort Approach
Yao Xu (Northeastern University), Gene Cooperman (Northeastern University)
Abstract
MPI is the de facto standard for parallel computing on a cluster of computers. Checkpointing is an important component in any strategy for software resilience and for long- running jobs that must be executed by chaining together time- bounded resource allocations. This work solves an old problem: a practical and general algorithm for transparent checkpointing of MPI that is both efficient and compatible with most of the latest network software. Transparent checkpointing is attractive due to its generality and ease of use for most MPI application developers. Earlier efforts at transparent checkpointing for MPI, one decade ago, had two difficult problems: (i) by relying on a specific MPI implementation tied to a specific network technology; and (ii) by failing to demonstrate sufficiently low runtime overhead. Problem (i) (network dependence) was already solved in 2019 by MANA’s introduction of split processes. Problem (ii) (efficient runtime overhead) is solved in this work. This paper introduces an approach that avoids these limitations, employing a novel topological sort to algorithmically determine a safe future synchronization point. We demonstrate the efficacy and scalability of our approach through both micro-benchmarks and a set of five real-world MPI applications, notably including the widely used VASP (Vienna Ab Initio Simulation Package), which is responsible for 11% of the workload on the Perlmutter supercomputer at Lawrence Berkley National Laboratory. VASP was previously cited as a special challenge for checkpointing, in part due to its multi-algorithm codes.
15:30-17:00
Session (7) IoT, Cloud, and Data Center (2 of 2)
International Conference Room
Chair: George Michelogiannakis (LBNL) Asif Ali Ahmed R (IEEE)
Enabling Workload-Driven Elasticity in MPI-based Ensembles
Enabling Workload-Driven Elasticity in MPI-based Ensembles
Md Rajib Hossen (The University of Texas at Arlington), Vanessa Sochat (Lawrence Livermore National Laboratory), Abhik Sarkar (Lawrence Livermore National Laboratory), Mohammad A. Islam (The University of Texas at Arlington), Daniel Milroy (Lawrence Livermore National Laboratory)
Abstract
Interdisciplinary workflows are evolving to accommodate the growing resource diversity and parallelism in modern computing systems. The necessity of integrating various components, including multi-scale simulations and Artificial Intelligence and Machine Learning (AI/ML) with ensemble methods, has made the workflows increasingly complex and challenging to manage using traditional High-Performance Computing (HPC) infrastructure. Cloud computing provides capabilities such as container orchestration, automation, and elasticity to manage the growing heterogeneity, scale, and complexity of HPC systems and workflows. Converged computing, a growing movement that integrates HPC and cloud technologies into a seamless environment, can provide a means to bridge the gap between needs and capabilities. In particular, ensemble-based HPC workflows can benefit from the potential efficiency improvements afforded by these capabilities. While MPI-based (Message Passing Interface) workflows have been demonstrated to scale using cloud-native orchestration in Kubernetes, there is little work on understanding the impact of autoscaling and elasticity on MPI-based workflows. In this study, we explore the cost and performance of elasticity applied to ensembles of MPI-based HPC simulations using the Flux Operator. We propose a workload-driven autoscaling algorithm that outperforms CPU utilization-based autoscaling for MPI-based ensembles. The efficiency gains afforded by elastic, autoscaled approaches for MPI-based ensembles are described. We demonstrate that the workload-driven algorithm can reduce ensemble completion time by up to 6x in comparison with CPU utilization-based autoscaling.
Geo-Distributed Analytical Streaming Architecture for IoT Platforms
Geo-Distributed Analytical Streaming Architecture for IoT Platforms
Mohammadreza Hoseinyfarahabady (The University of Sydney), Albert Y. Zomaya (The University of Sydney)
Abstract
The surge in real-time IoT data poses scalability and computational challenges, prompting the need for advanced architectural and technological solutions. Streamed data processing is increasingly adopted across industries, enhancing operational efficiency by extracting insights from vast, unstructured datasets. However, complex analytical tasks, like multi-join queries, often require stateful iterative calculations on high-volume, high-velocity data, challenging conventional programming models like MapReduce. This paper introduces an architectural model for application developers to create intricate streaming computational logic within an IoT platform. Our architecture supports scalable applications across distributed edge-tier nodes, particularly for iterative analytical operations on streamed data in near real-time. We discuss core concepts and a timestamp model attached to data items circulating between computational blocks, which can execute concurrently on different edge-tier nodes. Additionally, we detail a buffer management mechanism to dynamically adjust memory size in each computational block on nodes with limited capacity. This mechanism considers application performance requirements and runtime conditions to optimize buffer sizes. Performance evaluation against cloud-tier alternatives confirms the effectiveness of our solution. Experimental results show a 62\% reduction in p-99 delay compared to cloud-tier deployment with a database engine for analytical applications involving multi-join operations.
Seastar: A Cache-Efficient and Load-Balanced Key-Value Store on Disaggregated Memory
Seastar: A Cache-Efficient and Load-Balanced Key-Value Store on Disaggregated Memory
Jingwen Du (Huazhong University of Science and Technology), Fang Wang (Huazhong University of Science and Technology), Dan Feng (Huazhong University of Science and Technology), Dexin Zeng (Huazhong University of Science and Technology), Sheng Yi (Huazhong University of Science and Technology)
Abstract
In modern datacenters, memory disaggregation unpacks monolithic servers to build independent network-connected compute and memory pools, greatly improving resource utilization. Existing disaggregated memory systems adopt ownership sharing or ownership partitioning and they all show poor performance and scalability. The former generates multiple cache misses and multiple network round trips due to poor cache locality, while the latter fails to fully use resources on all CNs due to load imbalance. In this paper, we propose Seastar, a fast and scalable key-value store that achieves high cache locality as well as load balancing. To enable high concurrency and ensure linearizability, Seastar exploits a self-verification version chain to provide out-of-place atomic updates and ensure consistent reads. To improve cache locality, Seastar leverages a pair-based ownership assigning scheme to assign the processing permission of requests corresponding to each key to a CN pair through two independent hash functions. To ensure load balancing among CNs, Seastar proposes a decentralized power-of-two-choices routing scheme to route the requests to the less-loaded CNs in CN pairs for handling. Experimental results demonstrate that Seastar improves the throughput by up to 6.7x and significantly reduces the latency compared with state-of-the-art systems.
Session (8) Job Scheduling & Orchestration
Room 401/402
Chair: L., Lavanye (HPE) Mohamed Wahib (RIKEN R-CCS)
HEFTLess: A Bi-Objective Serverless Workflow Batch Orchestration on the Computing Continuum
HEFTLess: A Bi-Objective Serverless Workflow Batch Orchestration on the Computing Continuum
Reza Farahani (University of Klagenfurt), Narges Mehran (University of Klagenfurt), Sashko Ristov (University of Innsbruck), Radu Prodan (University of Klagenfurt)
Abstract
Extending cloud computing towards fog and edge computing yields a heterogeneous computing environment known as computing continuum. In recent years, increasing demands for scalable, cost-effective, and streamlined maintenance services have led application and service providers to prefer serverless models over monolithic and serverful processing. However, orchestrating the computing continuum in complex application workflows of serverless functions, each with distinct requirements, introduces new resource management and scheduling challenges. This paper introduces an orchestration service for concurrent serverless workflow processing across the computing continuum called HEFTLess. HEFTLess uses two deployment modes tailored to serve each workflow functions: predeployed and undeployed. We formulate the problem as a Binary Linear Programming (BLP) optimization model, incorporating multiple groups of constraints to minimize the overall completion time and monetary cost of executing workflow batches. Inspired by the Heterogeneous Earliest Finish Time (HEFT) algorithm, we propose a lightweight serverless workflow scheduling heuristic to cope with the high optimization time complexity in polynomial time. We evaluate HEFTLess using two machine learning-based serverless workflows on a real computing continuum testbed, including AWS Lambda and 325 combined on-promise and cloud instances from Exoscale, distributed across five geographic locations. The experimental results confirm that HEFTLess outperforms state-of-the-art methods in terms of both workflow batch completion time and cost.
Job Scheduling in High Performance Computing Systems with Disaggregated Memory Resources
Job Scheduling in High Performance Computing Systems with Disaggregated Memory Resources
Jie Li (Texas Tech University), George Michelogiannakis (Lawrence Berkeley National Laboratory), Samuel Maloney (Forschungszentrum Jülich), Brandon Cook (Lawrence Berkeley National Laboratory), Estela Suarez (Forschungszentrum Jülich), John Shalf (Lawrence Berkeley National Laboratory), Yong Chen (Texas Tech University)
Abstract
Disaggregated memory promises to meet applications' growing memory requirements while improving system resource utilization in high performance computing (HPC) systems. Compared to traditional systems where expensive resources such as CPUs, GPUs, and memories are assigned in units of nodes to jobs, systems with disaggregated memory introduce memory pools that can be shared among jobs; this fundamentally changes the goals of the job scheduler. In this paper, we propose a data-driven approach to evaluate job scheduling and resource configuration in HPC systems with disaggregated memory. To incorporate the memory requirement of jobs for both local and disaggregated memory resources and improve the system efficiency in open-science HPC systems, we introduce a novel job scheduling algorithm called FM. Our simulation results show that FM outperforms commonly-used job schedulers in terms of job bounded slowdown when the shared memory pool capacity is limited and in fairness under all conditions.
Fully Decentralized Data Distribution for Exascale-HPC: End of the Provider-Demander Matching Puzzle
Fully Decentralized Data Distribution for Exascale-HPC: End of the Provider-Demander Matching Puzzle
Mingtian Shao (National University of Defense Technology, China), Ruibo Wang (National University of Defense Technology, China), Kai Lu (National University of Defense Technology, China), Huijun Wu (National University of Defense Technology, China), Yiqin Dai (National University of Defense Technology, China), Wenzhe Zhang (National University of Defense Technology, China)
Abstract
For many years, in the HPC data distribution scenario, as the scale of the HPC system continues to increase, manufacturers have to increase the number of data providers to improve the IO parallelism to match the data demanders. In the era of Exascale Computing, this mode of decoupling the demander and provider has limited scalability and huge costs. In our view, only a distribution model in which the demander also acts as the provider can fundamentally cope with changes in scale and have the best scalability, which is called all-to-all data distribution mode in this paper. We design and implement the BitTorrent protocol on computing networks in HPC systems and propose FD3, a fully decentralized data distribution method. We design the Requested-to-Validated Table (RVT) and the Nearest and Longest consecutive piece Segment First (NLSF) policy based on the features of the HPC networking environment to improve the performance of FD3. Experimental results show that FD3 can scale smoothly to 11K+ computing nodes, and its performance is much better than that of the parallel file system. Compared with the original BitTorrent, the performance is improved by 7-11 times. FD3 shows the great potential of the all-to-all model in HPC data distribution scenarios. At the same time, the work of this paper can further stimulate the exploration of future distributed parallel file systems and provide a foundation and inspiration for the design of data access patterns for Exscale HPC systems.
17:15-18:45
Panel Discussion
International Conference Room
AI for Science: What should we do?
Panelists:
Sunita Chandrasekaran (U.Delaware, USA),
Estela Suarez (JSC/U.Bonn, Germany),
Ikko Hamamura (NVIDIA, Japan),
Mohamed Wahib (RIKEN R-CCS, Japan),
Rio Yokota (Tokyo Tech, Japan).
Moderator:
Kengo Nakajima (U.Tokyo/RIKEN R-CCS).
|
September 27
09:30-10:30
Keynote (3): Sunita Chandrasekaran
International Conference Room
Chair: Taisuke Boku (U.Tsukuba)
10:30-11:00
CLUSTER 2025 Presentation
International Conference Room
Chair: Taisuke Boku (U.Tsukuba)
Presenter: Michele Weiland (U. Edinburgh)
11:30-13:00
Session (9) Accelerators & In-Network Computing
International Conference Room
Chair: Lingqi Zhang (RIKEN R-CCS)
FT K-Means: A High-Performance K-Means on GPU with Fault Tolerance
FT K-Means: A High-Performance K-Means on GPU with Fault Tolerance
Shixun Wu (University of California, Riverside), Yitong Ding (University of California, Riverside), Yujia Zhai (University of California, Riverside), Jinyang Liu (University of California, Riverside), Jiajun Huang (University of California, Riverside), Zizhe Jian (University of California, Riverside), Huangliang Dai (University of California, Riverside), Sheng Di (Argonne National Laboratory), Bryan M. Wong (University of California, Riverside), Zizhong Chen (University of California, Riverside), Franck Cappello (Argonne National Laboratory)
Abstract
K-Means is a widely used algorithm in clustering, however, its efficiency is primarily constrained by the computational cost of distance computing. Existing implementations suffer from suboptimal utilization of computational units and lack resilience against soft errors. To address these challenges, we introduce FT K-Means, a high-performance GPU-accelerated implementation of K-Means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-Means with a template-based code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 and A100 GPUs demonstrate that FT K-Means without fault tolerance outperforms cuML's K-Means implementation, showing a performance increase of 10\%-300\% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-Means introduces only an overhead of 11\%, maintaining robust performance even with tens of errors injected per second.
ScalFrag: Efficient Tiled-MTTKRP with Adaptive Launching on GPUs
ScalFrag: Efficient Tiled-MTTKRP with Adaptive Launching on GPUs
Wenqing Lin (China University of Petroleum-Beijing), Hemeng Wang (China University of Petroleum-Beijing), Haodong Deng (China University of Petroleum-Beijing), Qingxiao Sun (China University of Petroleum-Beijing)
Abstract
Among the various methods employed for tensor decomposition, Canonical Polyadic Decomposition (CPD) stands out as a prominent choice, widely embraced across numerous scientific disciplines and practical applications due to its effectiveness in capturing multi-linear relationships. However, the computational efficacy of CPD is significantly hampered by the Matricized Tensor Times Khatri-Rao Product (MTTKRP) operation, which constitutes its primary bottleneck. While offloading the MTTKRP computation onto Graphics Processing Units (GPUs) has emerged as a prevalent strategy to leverage their parallel processing capabilities for enhancing performance, the inherent sparsity and irregular data access patterns intrinsic to these operations introduce new complexities. Addressing this challenge, we introduce an innovative methodology designed to accelerate sparse MTTKRP computations on GPU platforms. A key insight underlying our approach is the recognition that the optimal kernel launch configuration—a critical factor influencing GPU performance—varies considerably depending on the unique characteristics of the input tensor. We devise a dynamic kernel launch configuration selection mechanism to tackle this variability. This novel strategy autonomously identifies and applies the most advantageous launch setup tailored to each input tensor, optimizing computational efficiency. Additionally, we present a stream-based algorithm for sparse MTTKRP, further refining data access methodologies. By leveraging streaming architectures, our algorithm significantly improves data access efficiency, mitigating the bottlenecks assoiciated with the irregularities of sparse data accesses. The experimental results show that ScalFrag can find better performing settings with higher auto-tuning speed compared to the state-of-the-art works.
Leveraging high-performance data transfer to offload data management tasks to SmartNICs
Leveraging high-performance data transfer to offload data management tasks to SmartNICs
Scott Levy (Sandia National Laboratories), Whit Schonbein (Sandia National Laboratories), Craig Ulmer (Sandia National Laboratories)
Abstract
Network interface controllers (NICs) with general- purpose compute capabilities (‘SmartNICs’) present an oppor- tunity for reducing host application overheads by offloading non-critical tasks to the NIC. In addition to moving computa- tion, offloading requires that associated data associated is also transferred to the NIC. To meet this need, we introduce a high-performance, general-purpose data movement service that facilitates the offloading of tasks to SmartNICs: The SmartNIC Data Movement Service (SDMS). SDMS provides near-line- rate transfer bandwidths between the host and NIC. Moreover, SDMS’s In-transit Data Placement (IDP) feature can reduce (or even eliminate) the cost of serializing data on the NIC by performing the necessary data formatting during the transfer. To illustrate these capabilities, we provide in-depth case study using SDMS to offload data management operations related to Apache Arrow, a popular data format standard. For single-column tables, SDMS can achieve more than 87% of baseline throughput for data buffers that are 128 KiB or larger (and more than 95% of baseline throughput for buffers that are 1 MiB or larger) while also nearly eliminating the host and SmartNIC overhead associated with Arrow operations.
Session (10) Workflows
Room 401/402
Chair: Jay F Lofstead (Sandia National Lab)
DaYu: Optimizing Distributed Scientific Workflows by Decoding Dataflow Semantics and Dynamics
DaYu: Optimizing Distributed Scientific Workflows by Decoding Dataflow Semantics and Dynamics
Meng Tang (Illinois Institute of Technology), Jaime Cernuda (Illinois Institution of Technology), Jie Ye (Illinois Institution of Technology), Luanzheng Guo (Pacific Northwest National Laboratory), Nathan R. Tallent (Pacific Northwest National Laboratory), Anthony Kougkas (Illinois Institute of Technology), Xian-He Sun (Illinois Institute of Technology)
Abstract
The combination of ever-growing scientific datasets and distributed workflow complexity creates I/O performance bottlenecks due to data volume, velocity, and variety. Although the increasing use of descriptive data formats (e.g., HDF5, netCDF) helps organize these datasets, it also creates obscure bottlenecks due to the need to translate high level operations into file addresses and then into low-level I/O operations. To address this challenge, we introduce DaYu, a method and toolset for analyzing (a) semantic relationships between logical datasets and file addresses, (b) how dataset operations translate into I/O, and (c) the combination across entire workflows. DaYu's analysis and visualization enables identification of critical bottlenecks and reasoning about remediation. We describe our methodology and propose optimization guidelines. Evaluation on scientific workflows demonstrates up to 3.7x performance improvements in I/O time for obscure bottlenecks. The time and storage overhead for DaYu's time-ordered data is typically under 0.2% of runtime and 0.25% of data volume, respectively.
Sizey: Memory-Efficient Execution of Scientific Workflow Tasks
Sizey: Memory-Efficient Execution of Scientific Workflow Tasks
Jonathan Bader (Technische Universität Berlin), Fabian Skalski (Technische Universität Berlin), Fabian Lehmann (Humboldt-Universität zu Berlin), Dominik Scheinert (Technische Universität Berlin), Jonathan Will (Technische Universität Berlin), Lauritz Thamsen (University of Glasgow), Odej Kao (Technische Universität Berlin)
Abstract
As the amount of available data continues to grow in fields as diverse as bioinformatics, physics, and remote sensing, the importance of scientific workflows in the design and implementation of reproducible data analysis pipelines increases. When developing workflows, resource requirements must be defined for each type of task in the workflow. Typically, task types vary widely in their computational demands because they are simply wrappers for arbitrary black-box analysis tools. Furthermore, the resource consumption for the same task type can vary considerably as well due to different inputs. Since underestimating memory resources leads to bottlenecks and task failures, workflow developers tend to overestimate memory resources. However, overprovisioning of memory wastes resources and limits cluster throughput. Addressing this problem, we propose Sizey, a novel online memory prediction method for workflow tasks. During workflow execution, Sizey simultaneously trains multiple machine learning models and then dynamically selects the best model for each workflow task. To evaluate the quality of the model, we introduce a novel resource allocation quality (RAQ) score based on memory prediction accuracy and efficiency. Sizey's prediction models are retrained and re-evaluated online during workflow execution, continuously incorporating metrics from completed tasks. Our evaluation with a prototype implementation of Sizey uses metrics from five real-world scientific workflows from the popular nf-core framework and shows a median reduction in memory waste over time of 19.25% compared to the best-performing state-of-the-art baseline.
Phase-based Data Placement Optimization in Heterogeneous Memory
Phase-based Data Placement Optimization in Heterogeneous Memory
Jannis Klinkenberg (RWTH Aachen University), Clément Foyer (Université de Reims Champagne-Ardenne), Pierre Clouzet (Université de Bordeaux), Brice Goglin (Université de Bordeaux), Emmanuel Jeannot (Université de Bordeaux), Christian Terboven (RWTH Aachen University), Anara Kozhokanova (RWTH Aachen University)
Abstract
While scientific applications show increasing demand for memory speed and capacity, the performance gap between compute cores and the memory subsystem continues to spread. In response, heterogeneous memory systems integrating high-bandwidth memory (HBM) and non-volatile memory (NVM) alongside traditional DRAM are gaining traction. Despite the potential benefits of optimized memory selection for improved performance and efficiency, adapting applications to leverage diverse memory types often requires extensive modifications. Moreover, applications often comprise multiple execution phases with varying data access patterns. Since the capacity of the ``fastest'' memory is limited, relying solely on fixed data placement decisions may not yield optimal performance. Thus, considering allocation lifetimes and dynamically migrating data between memory types becomes imperative to ensure that performance-critical data for each phase resides in fast memory. To address these challenges, we developed a workflow incorporating memory access profiling, optimization techniques and a runtime system, which selects initial data placement for allocations and performs data migration during execution, considering the platform’s memory subsystem characteristics and capacities. We formalize the optimization problems for initial and phase-based data placement and propose heuristics derived from memory profiling metrics to solve it. Additionally, we outline the implementation of these approaches, including allocation interception to enforce placement decisions. Experiments conducted with several applications on an Intel Ice Lake (DRAM+NVM) and Sapphire Rapids (HBM+DRAM) system demonstrate that our methodology can effectively bridge the performance gap between slow and fast memory in heterogeneous memory environments.
13:00-14:00
Lunch Break
(Lunch box is provided for attendee)
International Conference Room
Student Job Fair Lunch (inc. Supporter Companies)
(Lunch box is provided for attendee)
Room 401/402
14:00-15:30
Session (11) Applications
International Conference Room
Chair: Jiajun Huang (UC Riverside)
Xphase3d: Memory-Distributed Phase Retrieval for Reconstructing Large-Scale 3D Density Maps of Biological Macromolecules
Xphase3d: Memory-Distributed Phase Retrieval for Reconstructing Large-Scale 3D Density Maps of Biological Macromolecules
Wenyang Zhao (RIKEN Center for Computational Science), Osamu Miyashita (RIKEN Center for Computational Science), Miki Nakano (RIKEN Center for Computational Science), Florence Tama (Nagoya University/RIKEN Center for Computational Science)
Abstract
Phase retrieval is a crucial step in processing data from advanced X-ray diffraction imaging experiments to analyze the 3D structure of biological macromolecules. However, when the 3D volume is large-scale and consists of numerous fine voxels, performing phase retrieval on it requires a significant amount of memory, often exceeding the capacity of individual workstations. To address this issue, we developed xphase3d, an open-source software package for performing multiprocessing parallel 3D phase retrieval to utilize distributed memory in clusters and supercomputers. Xphase3d has been successfully deployed on the supercomputer Fugaku and has contributed to research in the fields of structural biology and X-ray analysis. It is also compatible with other high-performance computing systems.
Accuracy-Efficiency Optimization for Multi-Stage Small Object Detection in Surveillance Video with Collaborative Frame Sampling
Accuracy-Efficiency Optimization for Multi-Stage Small Object Detection in Surveillance Video with Collaborative Frame Sampling
Chunhong Du (Tianjin University), Shanjiang Tang (Tianjin University), Song Meng (Tianjin University), Jiekai Gou (Tianjin University), Ce Yu (Tianjin University), Yusen Li (Nankai University), Hao Fu (National Supercomputing Center of Tianjin), Ye Tian (Tianjin University), Ding Yuan (Tianjin University)
Abstract
In video analytics, accuracy and efficiency are two important metrics and there tend to be a tradeoff between each other. In this paper, we consider accuracy-efficiency optimization for small object detection in surveillance video, which is important and has been widely used in many scenarios such as license plate detection in the traffic domain. Given that small objects tend to being attached to big objects, multi-stage object detection is supposed to be an effective approach to achieve high accuracy for small objects by detecting big objects first and then small objects within the ROIs (Region of interests) of big objects. However, existing studies considered the accuracy-efficiency optimization for small object detection only within the single-stage scenario by changing the frame resolution or sampling rate configuration of video data, which are not suitable for multi-stage detection given that its accuracy-efficiency result is determined by the results of all stages jointly. In this paper, we propose an Adaptive and Collaborative frame Sampling approach named ACS for accuracy-efficiency optimization in the multi-stage small object detection. To improve the efficiency significantly while guaranteeing a given accuracy threshold, ACS dynamically adjusts the sampling rates of all stages collaboratively and periodically using the Karush-Kuhn-Tucker (KKT) condition based on the Lagrangian multiplier method. Additionally, we introduce a tuning knob to allow users to flexibly balance accuracy and efficiency, while ensuring a given accuracy threshold η. Extensive experiments demonstrate the effectiveness of our approach in improving detection efficiency while guaranteeing diverse accuracy requirements.
Modernizing an Operational Real-time Tsunami Simulator to Support Diverse Hardware Platforms
Modernizing an Operational Real-time Tsunami Simulator to Support Diverse Hardware Platforms
Keichi Takahashi (Tohoku University), Takahashi Abe (Tohoku University), Akihiro Musa (NEC Corporation), Yoshihiko Sato (NEC Solution Innovators), Yoichi Shimomura (NEC Solution Innovators), Hiroyuki Takizawa (Tohoku University), Shunichi Koshimura (Tohoku University)
Abstract
To issue early warnings and rapidly initiate disaster responses after tsunami damage, various tsunami inundation forecast systems have been deployed worldwide. Japan’s Cabinet Office operates a forecast system that utilizes supercomputers to perform tsunami propagation and inundation simulation in real-time. Although this real-time approach is able to produce significantly more accurate forecasts than the conventional database-driven approach, its wider adoption was hindered because it was specifically developed for vector supercomputers. In this paper, we migrate the simulation code to modern CPUs and GPUs in a minimally invasive manner to reduce the testing and maintenance costs. A directive-based approach is employed to retain the structure of the original code while achieving performance portability, and hardware-specific optimizations including load balance improvement for GPUs are applied. The migrated code runs efficiently on recent CPUs, GPUs and vector processors: a six-hour tsunami simulation using over 47 million cells completes in less than 2.5 minutes on 32 Intel Sapphire Rapids CPUs and 1.5 minutes on 32 NVIDIA H100 GPUs. These results demonstrate that the code enables broader access to accurate tsunami inundation forecasts.
Session (12) Storage & I/O
Room 401/402
Chair: Reza HoseinyF (University of Sydney)
I/O Behind the Scenes: Bandwidth Requirements of HPC Applications With Asynchronous I/O
I/O Behind the Scenes: Bandwidth Requirements of HPC Applications With Asynchronous I/O
Ahmad Tarraf (Technical University of Darmstadt), Javier Fernandez Muñoz (University Carlos III of Madrid), David E. Singh (University Carlos III of Madrid), Taylan Özden (Technical University of Darmstadt), Jesus Carretero (University Carlos III of Madrid), Felix Wolf (Technical University of Darmstadt)
Abstract
I/O bandwidth is a critical resource in an HPC cluster. As with all shared resources, its availability is impacted significantly by the users and the applications they execute. Without proper restrictions, jobs consuming more prominent portions of the I/O bandwidth can severely affect other jobs by notably prolonging their runtime. In such a context, applications that perform asynchronous I/O bring unique properties that allow for the reduction of such effects. That is, by limiting the bandwidth to the required one to perform the I/O in the background of the compute phases, I/O bursts can be flattened without significantly prolonging the application time, if at all. Hence, the bandwidth consumption of such applications is limited to what they need, sparing much of the system bandwidth to other applications. At the same time, these applications achieve higher parallel efficiency due to the overlapping of different resources (e.g., compute and I/O). This paper shows these aspects and demonstrates our approach to find the required bandwidth for applications that use asynchronous I/O. Moreover, we apply it automatically using an MPI implementation of a bandwidth limitation approach at the application level. We validate our approach with several experiments on a large production cluster and show the impact of our approach on the application behavior and its importance for the system throughout.
FINCHFS: Design of Ad-Hoc File System for I/O Heavy HPC Workloads
FINCHFS: Design of Ad-Hoc File System for I/O Heavy HPC Workloads
Sohei Koyama (University of Tsukuba), Kohei Hiraga (University of Tsukuba), Osamu Tatebe (University of Tsukuba)
Abstract
Although the performance improvements in parallel file systems have been significant, the rise of data science and deep learning using Python has introduced new I/O requirements. We redefine ad-hoc file systems as a complement to parallel file systems by specializing in requirements that cannot be met by improvements to parallel file systems. Ad hoc file systems require extremely high metadata performance and the ability to scale to create and read large numbers of files in parallel in a single directory. Therefore, it is necessary to process a large number of small RPCs with low latency and high throughput, which cannot be achieved with existing ad-hoc file systems. In this research, we propose a new ad-hoc file system, FINCHFS, and realize the truly desired ad-hoc file system using intranode shared-nothing architecture and number-aware hashing. The contribution of the intra-node shared-nothing architecture is the ability to run multiple iterative server processes on each node to achieve high IOPS using many-core. The contribution of number-aware hashing is to alleviate tail latency degradation due to the uneven distribution of requests to servers. In the evaluation using 64 nodes on the Pegasus supercomputer, we achieved 32.5 MIOPS in mdtest-hard-write.
A High-Performance and Fast-Recovery Scheme for Secure Non-Volatile Memory Systems
A High-Performance and Fast-Recovery Scheme for Secure Non-Volatile Memory Systems
Yujie Shi (Huazhong University of Science and Technology), Yu Hua (Huazhong University of Science and Technology), Jianming Huang (Huazhong University of Science and Technology)
Abstract
Non-Volatile Memory (NVM) delivers high performance due to efficiently coalescing the properties of memory and storage while suffering from high security risks. To protect data, NVM systems introduce secure mechanisms, e.g., counter mode encryption and integrity verification, which necessitate extra security metadata. Unfortunately, these metadata are possibly lost when the system crashes, making data inaccessible. To ensure normal system operation after reboot, it is critical to recover these security metadata. The SGX-style integrity tree (SIT) can provide integrity verification for user data with high performance. Unfortunately, it is challenging for SIT to recover and verify the stale tree nodes due to the complex inter-layer dependency and the root inconsistency problem. In this paper, we propose Steins, to bridge the gap between fast recovery and high performance in secure NVM systems. Based on the consistency between the lost node and their persistent child nodes, Steins proposes an efficient counter generation scheme to make SIT recoverable. Moreover, Steins utilizes the offset-based tracking mechanism to locate the stale nodes during recovery. More importantly, to prevent attacks during recovery, Steins introduces efficient trust bases for verification. The evaluation results show that compared with state-of-the-art recovery schemes, Steins shows high runtime performance and short recovery time, while supporting low metadata storage overhead.
15:35-16:05
Award and Closing Session
International Conference Room
Chair: Kengo Nakajima (U. Tokyo/RIKEN R-CCS)
Best Student Poster & Best Poster Awards (Takeshi Fukaya, Posters Chair, Hokkaido U.)
Best Student Paper & Best Paper Awards (Mohamed Wahib, TPC Co-Chair, RIKEN R-CCS)
Closing Remarks (James Lin, General Co-Chair, Shanghai Jiao Tong U.)
|
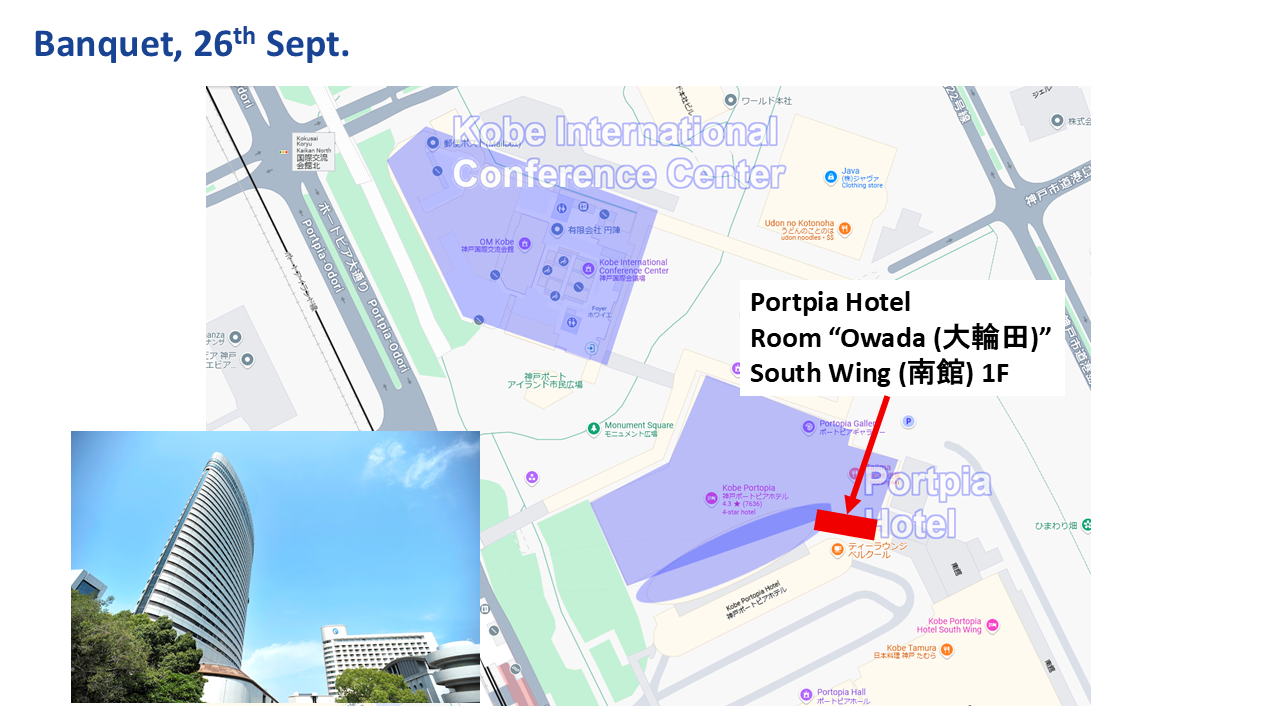{kind=link}
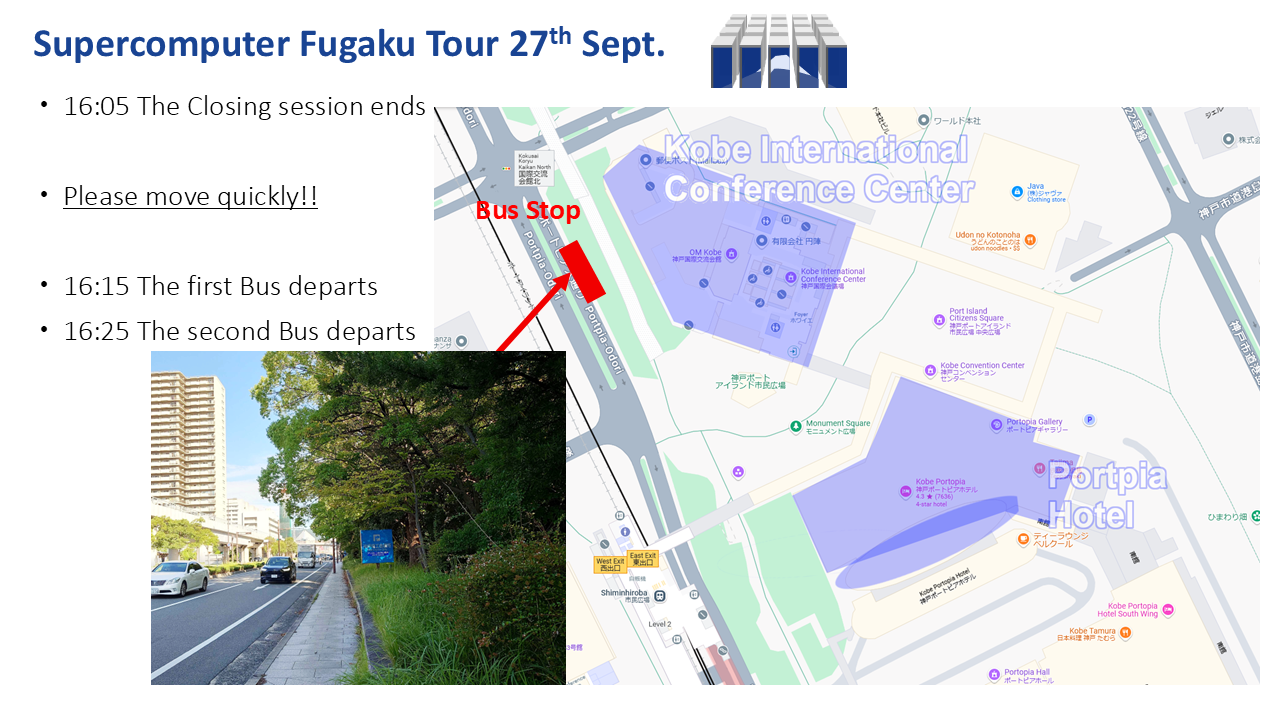{kind=link}